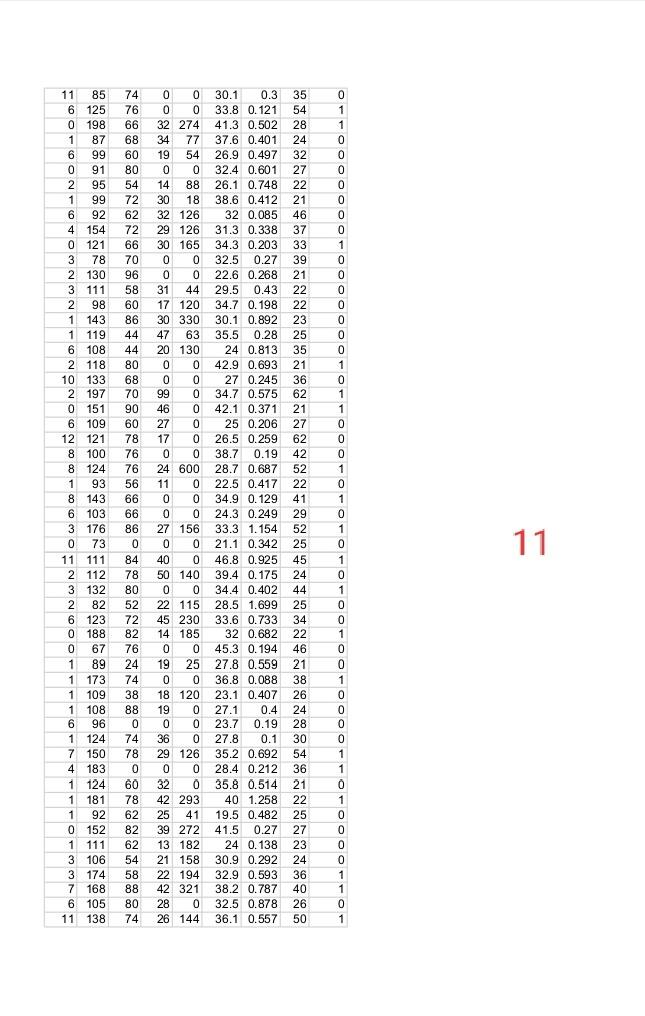
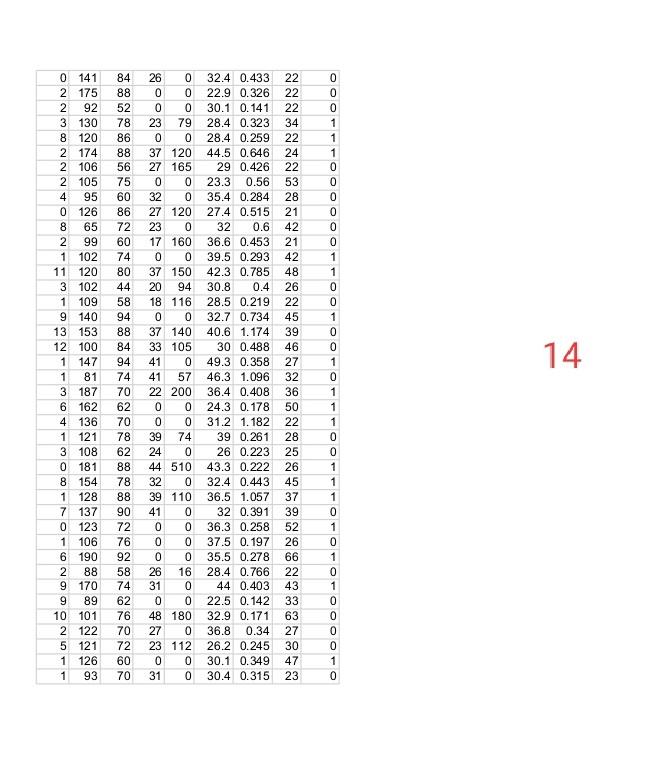
Please write Python codes using “pima-indian-diabetes” data sets as attached with this question. Goal: In this question, you will implement Logistic Regression, Regularized Data sets: This dataset describes the medical records for Pima Indians and whether or not each Fields description follow: pedi = Diabetes pedigree function Your Task:
(L2) Logistic Regression. The goal of
this question is to give you
experience in implementation of Logistic
Regression and analyze the
hyperparameter tuning in case of Regularized Logistic Regression.
The dataset that you use in this project is “pima-indians-diabetes”. Please find the attachments.
patient will have an onset of diabetes within year.
preg = Number of times pregnant
plas = Plasma glucose concentration a 2 hours in an oral glucose tolerance test
pres = Diastolic blood pressure (mm Hg)
skin = Triceps skin fold thickness (mm)
test = 2-Hour serum insulin (mu U/ml)
mass = Body mass index (weight in kg/(height in m)^2)
age = Age (years)
class = Class variable (1:tested positive for diabetes, 0: tested negative for diabetes)
Question-1: Using attached data set of “pima-indian-diabetes”. Implementing Logistic Regression using given 8 features in the data.



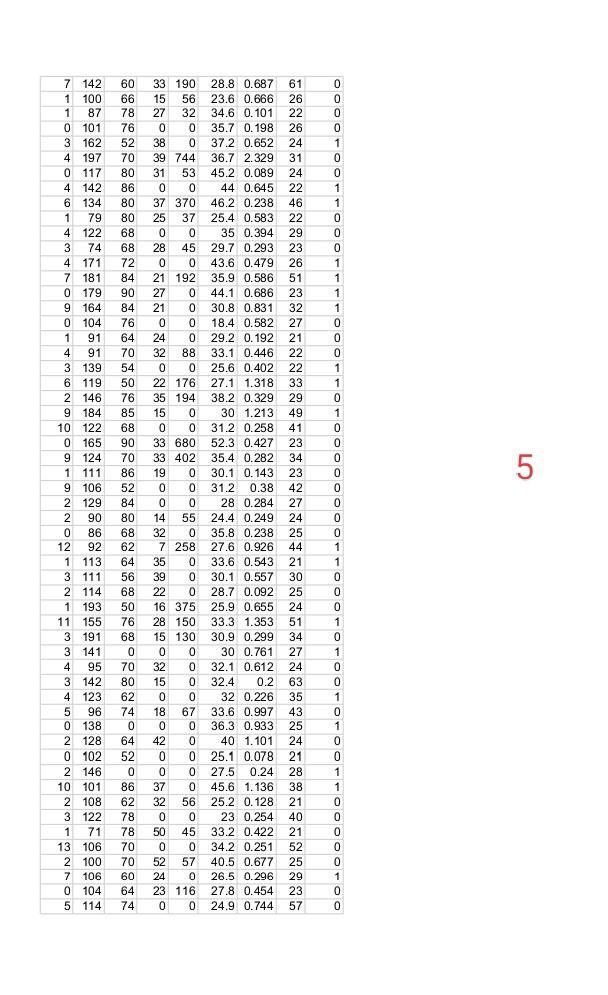

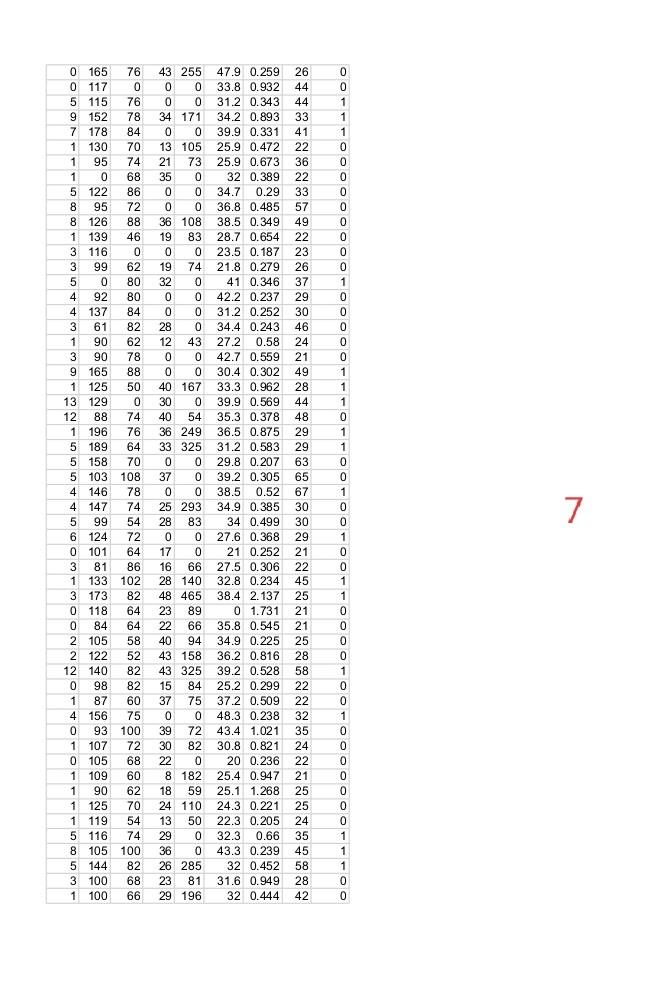
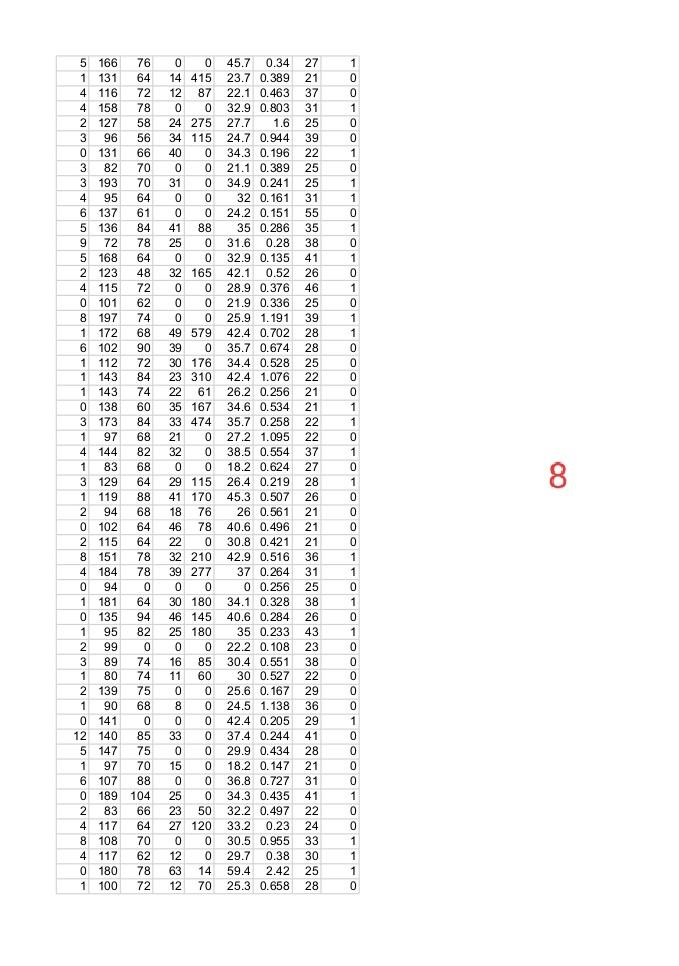
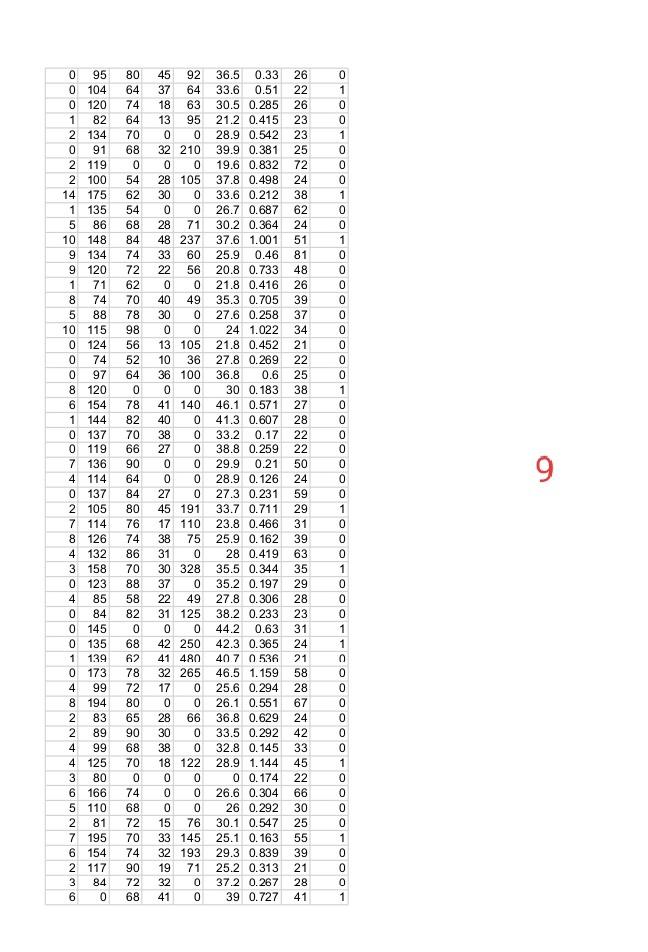



Expert Answer
OR