(Solved) : Get Rid Nan Data Inf Data Listed Fix Error Running Smote Dataset Python Neural Network Dat Q43929688 . . .
How to get rid of NaN data and Inf data listed below to fix thiserror while running SMOTE on a dataset in python for a neuralnetwork.
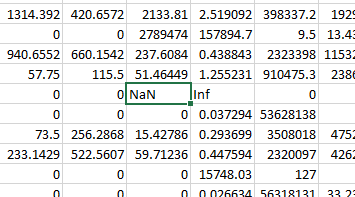
Data in csv-
error
![In [4]: smote = SMOTE(minority) X_smotetrain, y_smotetrain = smote.fit_sample(x_train, dummy yone) print(x_smotetrain.shape](https://media.cheggcdn.com/media/d51/d51509d0-462b-47be-a545-15b706a5f9f4/phpLQlQVo.png)
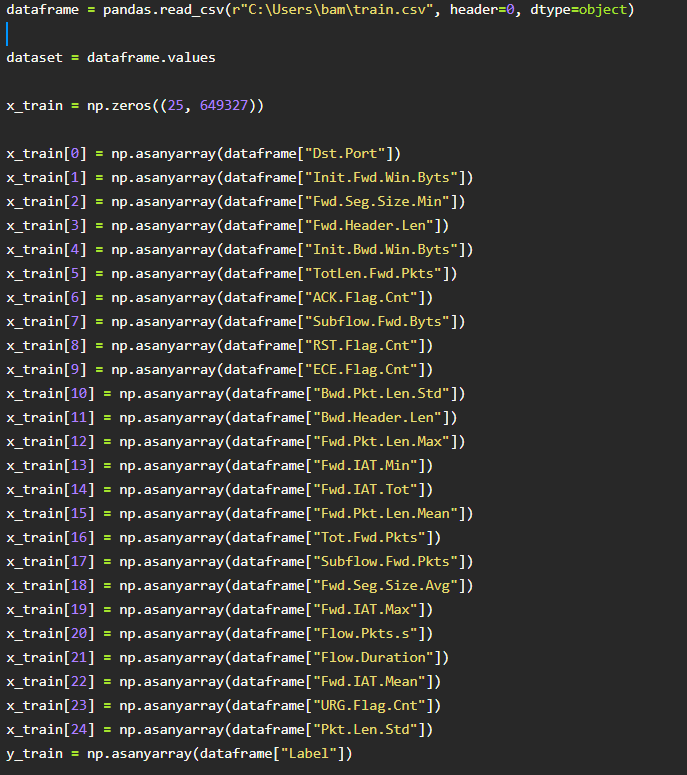
data declared for data frame
1314.392 420.6572 2133.81 2.519092 398337.2 192! 0 0 2789474 157894.7 9.5 13.4 940.6552 660.1542 237.6084 0.438843 2323398 1153 57.75 115.5 51.46449 1.255231 910475.3 238 0 0 NaN Inf 0 0 0 0.037294 53628138 73.5 256.2868 15.42786 0.293699 3508018 475 233.1429 522.5607 59.71236 0.447594 2320097 426. 0 0 015748.03 127 n n n n026624 56212121 22 23 In [4]: smote = SMOTE(‘minority’) X_smotetrain, y_smotetrain = smote.fit_sample(x_train, dummy yone) print(x_smotetrain.shape, y_smotetest.shape) ValueError Traceback (most recent call last) <ipython-input-4-af6609b17d24> in <module> 1 smote = SMOTE(‘minority’) —-> 2 x_smotetrain, y_smotetrain = smote.fit_sample(x_train, dummy_yone), 3 print(x_smotetrain.shape, y_smotetest.shape) Anaconda3lib site-packagesimblearn base.py in fit_resample(self, x, y) check_classification_targets(y) x, y, binarize_y = self._check_x_y(x, y) —> 79 self.sampling strategy_ = check_sampling strategy – Anaconda3libsite-packagesimblearnbase.py in _check_x_y(x, y), 135 def _check_x_y(x, y): 136 y, binarize_y = check_target_type(y, indicate_one_vs_all=True), –> 137 X, y = check_x_y(x, y, accept_sparse=[‘csr’, ‘CSC’]), 138 return X, Y, binarize_y 139 – Anaconda3libsite-packagessklearn utils validation.py in check_x_y(x, y, accept_sparse, accept_large_sparse, dtype, order, copy, force _all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, warn_on_dtype, estimator), 717 ensure_min_features=ensure_min_features, 718 warn_on_dtype=warn_on_dtype, –> 719 estimator-estimator) 720 if multi_output: y = check_array(y, ‘csr’, force_all_finite=True, ensure_2d=False, 721 – Anaconda3libsite-packagessklearnutils validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, fo rce_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, warn_on_dtype, estimator) 540 if force_all_finite: 541 _assert_all_finite(array, –> 542 allow_nan=force_all_finite == ‘allow-nan’) 543 544 if ensure_min_samples > @: – Anaconda3lib site-packagessklearn utils validation.py in _assert_all_finite(x, allow_nan) not allow_nan and not np.isfinite(x).all(): type_err = ‘infinity’ if allow_nan else ‘NaN, infinity’ -> 56 raise ValueError(msg_err.format(type_err, X.dtype)) 57 # for object dtype data, we only check for NaNS (GH-13254) 58 elif x.dtype == np.dtype(“object”) and not allow_nan: ValueError: Input contains NaN, infinity or a value too large for dtype(‘float64’). dataframe = pandas.read_csv(r”C:Usersbam train.csv”, header=0, dtype=object) dataset = dataframe.values x_train = np.zeros((25, 649327)) x_train[@] = np.asanyarray(dataframe[“Dst.Port” 1) x_train[1] = np.asanyarray(dataframe[ “Init.Fwd. Win.Byts” 1), x_train[2] = np.asanyarray(dataframe[ “Fwd. Seg.Size.Min” 1), x_train[3] = np.asanyarray(dataframe [ “Fwd. Header.Len”]) x train[4] = np.asanyarray(dataframe[“Init.Bwd.Win.Byts”]), x_train[5] = np.asanyarray(dataframe[ “Totlen.Fwd.Pkts”]) x_train[6] = np.asanyarray(dataframe[“ACK.Flag.cnt”]), x_train[7] = np.asanyarray(dataframe[ “Subflow.Fwd. Byts” ]), x_train[8] = np.asanyarray(dataframe[ “RST.Flag. Ont” 1), x_train[9] = np.asanyarray(dataframe[ “ECE. Flag.Cnt”]), x_train[10] = np.asanyarray(dataframe[ “Bwd.Pkt.Len.Std”]), x_train[11] = np.asanyarray(dataframe[ “Bwd. Header.Len”]), x_train[12] = np.asanyarray(dataframe[ “Fwd.Pkt. Len .Max” 1), x_train[13] = np.asanyarray(dataframe[ “Fwd. IAT.Min”]) x_train[14] = np.asanyarray(dataframe[ “Fwd. IAT. Tot”]), x_train[15] = np.asanyarray(dataframe[ “Fwd.Pkt.Len.Mean”]), x_train[16] = np.asanyarray(dataframe[ “Tot.Fwd.Pkts”]), x_train[17] = np.asanyarray(dataframe[ “Subflow.Fwd.Pkts”]), x_train[18] = np.asanyarray(dataframe[ “Fwd. Seg.Size.Avg”]), x_train[19] = np.asanyarray(dataframe[ “Fwd. IAT.Max”]), x_train[20] = np.asanyarray(dataframe[ “Flow.Pkts.s”]), x_train[21] = np.asanyarray(dataframe[ “Flow.Duration”]) x_train[22] = np.asanyarray(dataframe[ “Fwd. IAT. Mean”]), x_train[23] = np.asanyarray(dataframe[ “URG.Flag. Ont”]), x_train[24] = np.asanyarray(dataframe[ “Pkt.Len.Std”]), y_train = np.asanyarray(dataframe[ “Label”]) Show transcribed image text 1314.392 420.6572 2133.81 2.519092 398337.2 192! 0 0 2789474 157894.7 9.5 13.4 940.6552 660.1542 237.6084 0.438843 2323398 1153 57.75 115.5 51.46449 1.255231 910475.3 238 0 0 NaN Inf 0 0 0 0.037294 53628138 73.5 256.2868 15.42786 0.293699 3508018 475 233.1429 522.5607 59.71236 0.447594 2320097 426. 0 0 015748.03 127 n n n n026624 56212121 22 23
In [4]: smote = SMOTE(‘minority’) X_smotetrain, y_smotetrain = smote.fit_sample(x_train, dummy yone) print(x_smotetrain.shape, y_smotetest.shape) ValueError Traceback (most recent call last) in 1 smote = SMOTE(‘minority’) —-> 2 x_smotetrain, y_smotetrain = smote.fit_sample(x_train, dummy_yone), 3 print(x_smotetrain.shape, y_smotetest.shape) Anaconda3lib site-packagesimblearn base.py in fit_resample(self, x, y) check_classification_targets(y) x, y, binarize_y = self._check_x_y(x, y) —> 79 self.sampling strategy_ = check_sampling strategy – Anaconda3libsite-packagesimblearnbase.py in _check_x_y(x, y), 135 def _check_x_y(x, y): 136 y, binarize_y = check_target_type(y, indicate_one_vs_all=True), –> 137 X, y = check_x_y(x, y, accept_sparse=[‘csr’, ‘CSC’]), 138 return X, Y, binarize_y 139 – Anaconda3libsite-packagessklearn utils validation.py in check_x_y(x, y, accept_sparse, accept_large_sparse, dtype, order, copy, force _all_finite, ensure_2d, allow_nd, multi_output, ensure_min_samples, ensure_min_features, y_numeric, warn_on_dtype, estimator), 717 ensure_min_features=ensure_min_features, 718 warn_on_dtype=warn_on_dtype, –> 719 estimator-estimator) 720 if multi_output: y = check_array(y, ‘csr’, force_all_finite=True, ensure_2d=False, 721 – Anaconda3libsite-packagessklearnutils validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, fo rce_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, warn_on_dtype, estimator) 540 if force_all_finite: 541 _assert_all_finite(array, –> 542 allow_nan=force_all_finite == ‘allow-nan’) 543 544 if ensure_min_samples > @: – Anaconda3lib site-packagessklearn utils validation.py in _assert_all_finite(x, allow_nan) not allow_nan and not np.isfinite(x).all(): type_err = ‘infinity’ if allow_nan else ‘NaN, infinity’ -> 56 raise ValueError(msg_err.format(type_err, X.dtype)) 57 # for object dtype data, we only check for NaNS (GH-13254) 58 elif x.dtype == np.dtype(“object”) and not allow_nan: ValueError: Input contains NaN, infinity or a value too large for dtype(‘float64’).
dataframe = pandas.read_csv(r”C:Usersbam train.csv”, header=0, dtype=object) dataset = dataframe.values x_train = np.zeros((25, 649327)) x_train[@] = np.asanyarray(dataframe[“Dst.Port” 1) x_train[1] = np.asanyarray(dataframe[ “Init.Fwd. Win.Byts” 1), x_train[2] = np.asanyarray(dataframe[ “Fwd. Seg.Size.Min” 1), x_train[3] = np.asanyarray(dataframe [ “Fwd. Header.Len”]) x train[4] = np.asanyarray(dataframe[“Init.Bwd.Win.Byts”]), x_train[5] = np.asanyarray(dataframe[ “Totlen.Fwd.Pkts”]) x_train[6] = np.asanyarray(dataframe[“ACK.Flag.cnt”]), x_train[7] = np.asanyarray(dataframe[ “Subflow.Fwd. Byts” ]), x_train[8] = np.asanyarray(dataframe[ “RST.Flag. Ont” 1), x_train[9] = np.asanyarray(dataframe[ “ECE. Flag.Cnt”]), x_train[10] = np.asanyarray(dataframe[ “Bwd.Pkt.Len.Std”]), x_train[11] = np.asanyarray(dataframe[ “Bwd. Header.Len”]), x_train[12] = np.asanyarray(dataframe[ “Fwd.Pkt. Len .Max” 1), x_train[13] = np.asanyarray(dataframe[ “Fwd. IAT.Min”]) x_train[14] = np.asanyarray(dataframe[ “Fwd. IAT. Tot”]), x_train[15] = np.asanyarray(dataframe[ “Fwd.Pkt.Len.Mean”]), x_train[16] = np.asanyarray(dataframe[ “Tot.Fwd.Pkts”]), x_train[17] = np.asanyarray(dataframe[ “Subflow.Fwd.Pkts”]), x_train[18] = np.asanyarray(dataframe[ “Fwd. Seg.Size.Avg”]), x_train[19] = np.asanyarray(dataframe[ “Fwd. IAT.Max”]), x_train[20] = np.asanyarray(dataframe[ “Flow.Pkts.s”]), x_train[21] = np.asanyarray(dataframe[ “Flow.Duration”]) x_train[22] = np.asanyarray(dataframe[ “Fwd. IAT. Mean”]), x_train[23] = np.asanyarray(dataframe[ “URG.Flag. Ont”]), x_train[24] = np.asanyarray(dataframe[ “Pkt.Len.Std”]), y_train = np.asanyarray(dataframe[ “Label”])
Expert Answer
Answer to How to get rid of NaN data and Inf data listed below to fix this error while running SMOTE on a dataset in python for a …
OR